背景
本文记录租用云平台算力进行训练,减轻本机使用显卡的load。由于笔记本本身显卡能耗受限、散热不佳、显存受限等问题,我个人建议尽量避免笔记本overload。
关于如何使用云平台进行训练,需要具备cuda、Linux、yolo的一些知识。
此处以vastai平台使用yolov8训练模型为例。
放弃国内算力平台
此时我在国外,最开始选择了国内算力平台“智星云”(https://gpu.ai-galaxy.cn/),但是很快发现一些网络问题。服务器并非具备独立IP,只是VPS向外映射SSH或RDP端口做了内网穿透,不知是否是GFW问题导致网络非常卡顿、RDP断断续续问题。因为无法解决比较快速的上传训练文件(2.5GB)左右,且其下载国外服务器文件速度过慢,遂放弃。
选择国外算力平台vastai
此处以vastai为例 https://cloud.vast.ai/
注册账号
使用Google账号就可以登陆网站
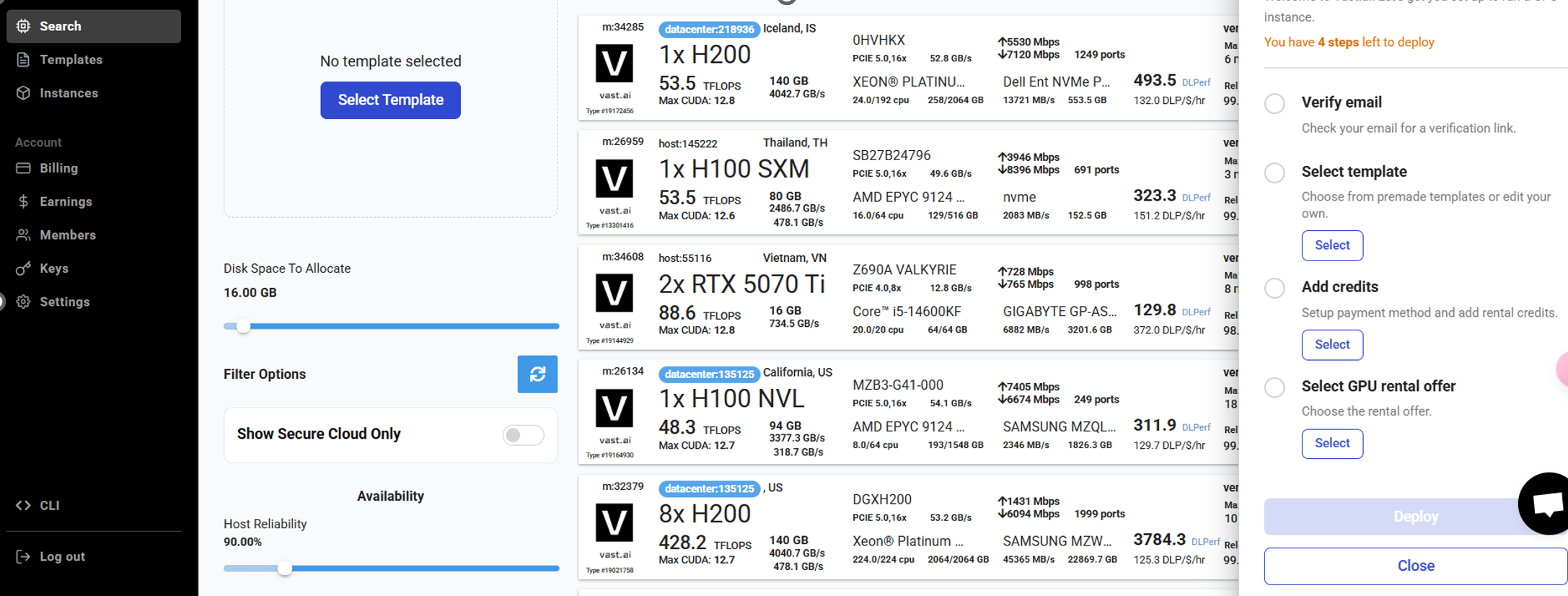
需要将右侧的四个要求解决才可以完成租赁。
验证邮箱
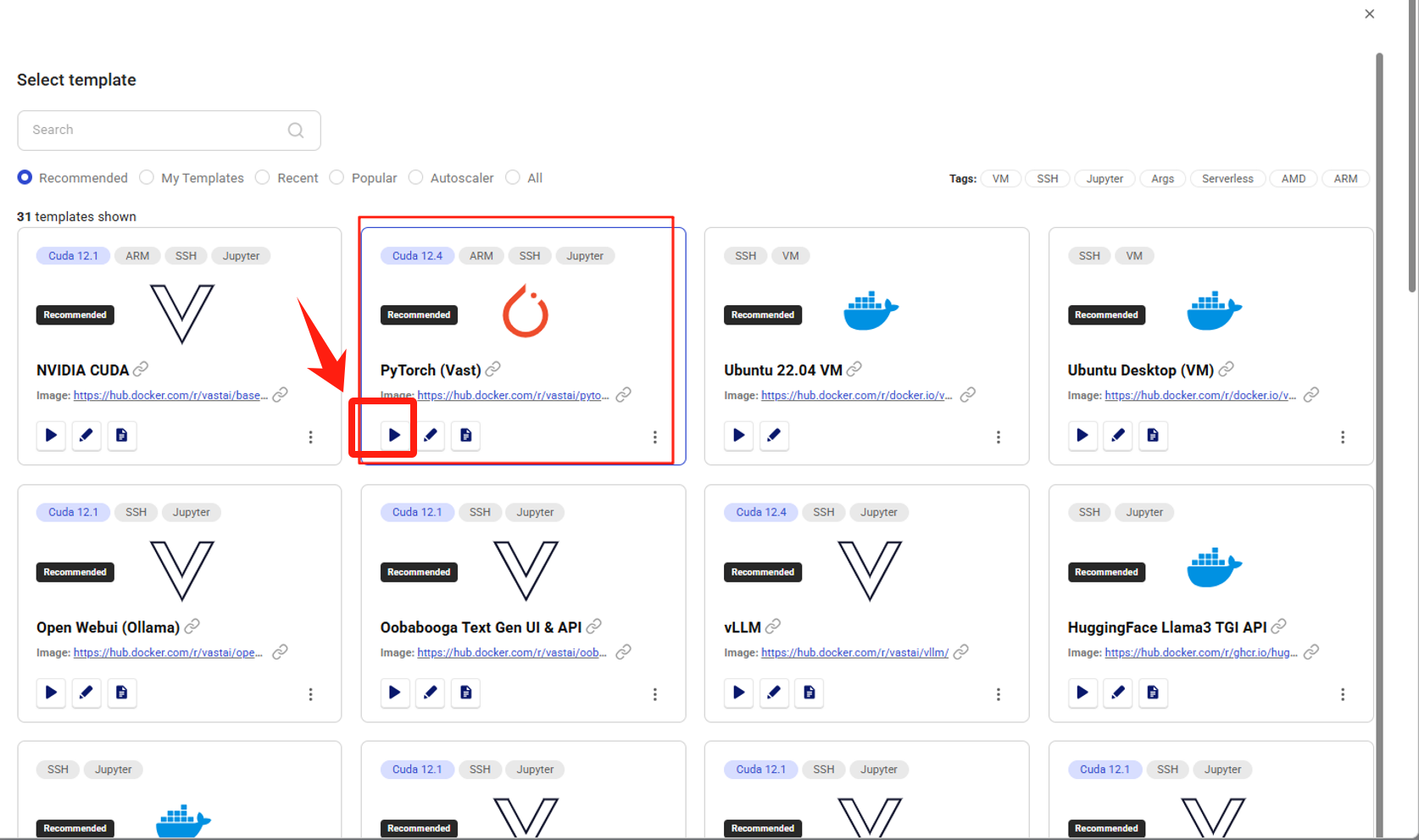
选择template,此处选择现成的pytorch。点击torch下面那个小播放键 就选择了。
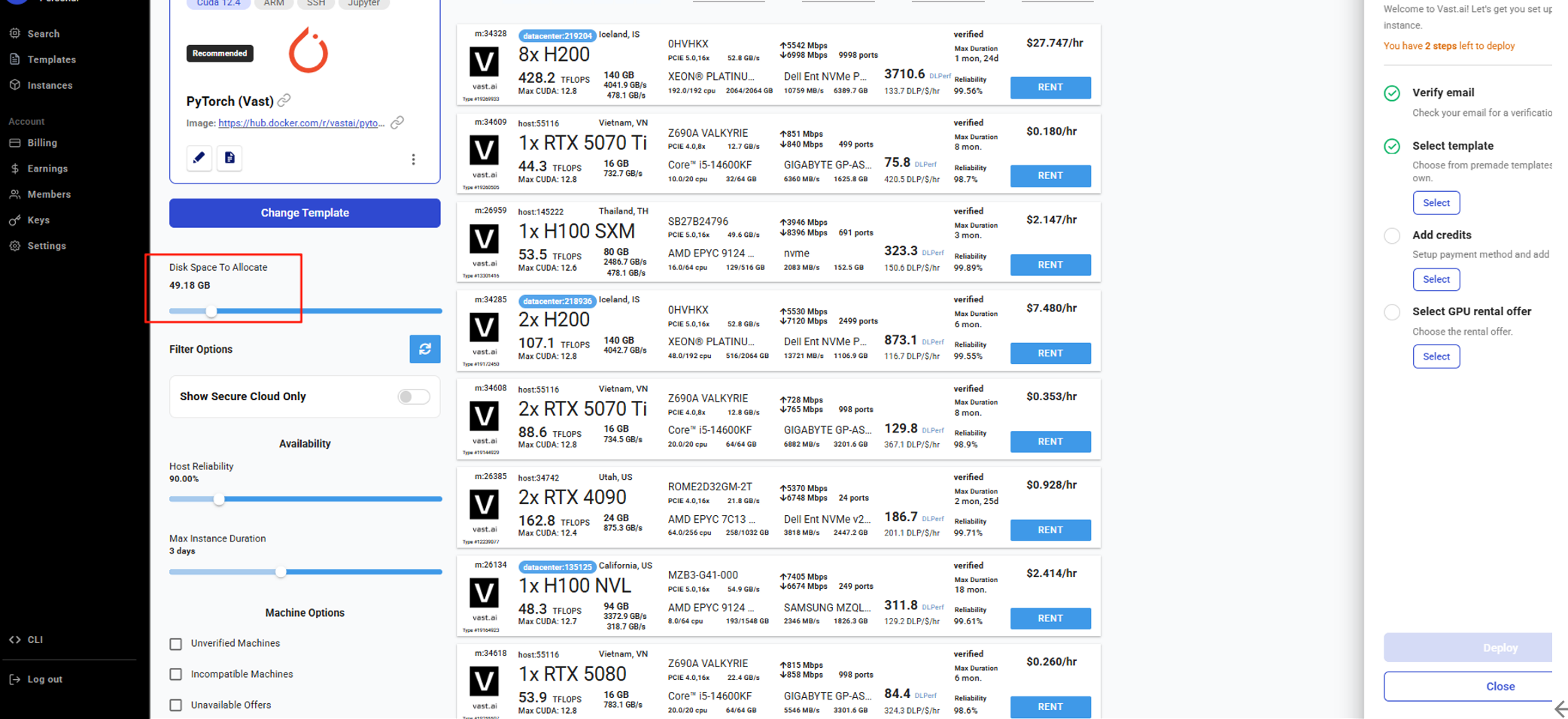
把磁盘拉到50GB及以上,磁盘太小一般很容易出现杂七杂八的问题,因此disk不要小的太极限。
充钱,略。
选购GPU
最后选择具体的GPU rent.
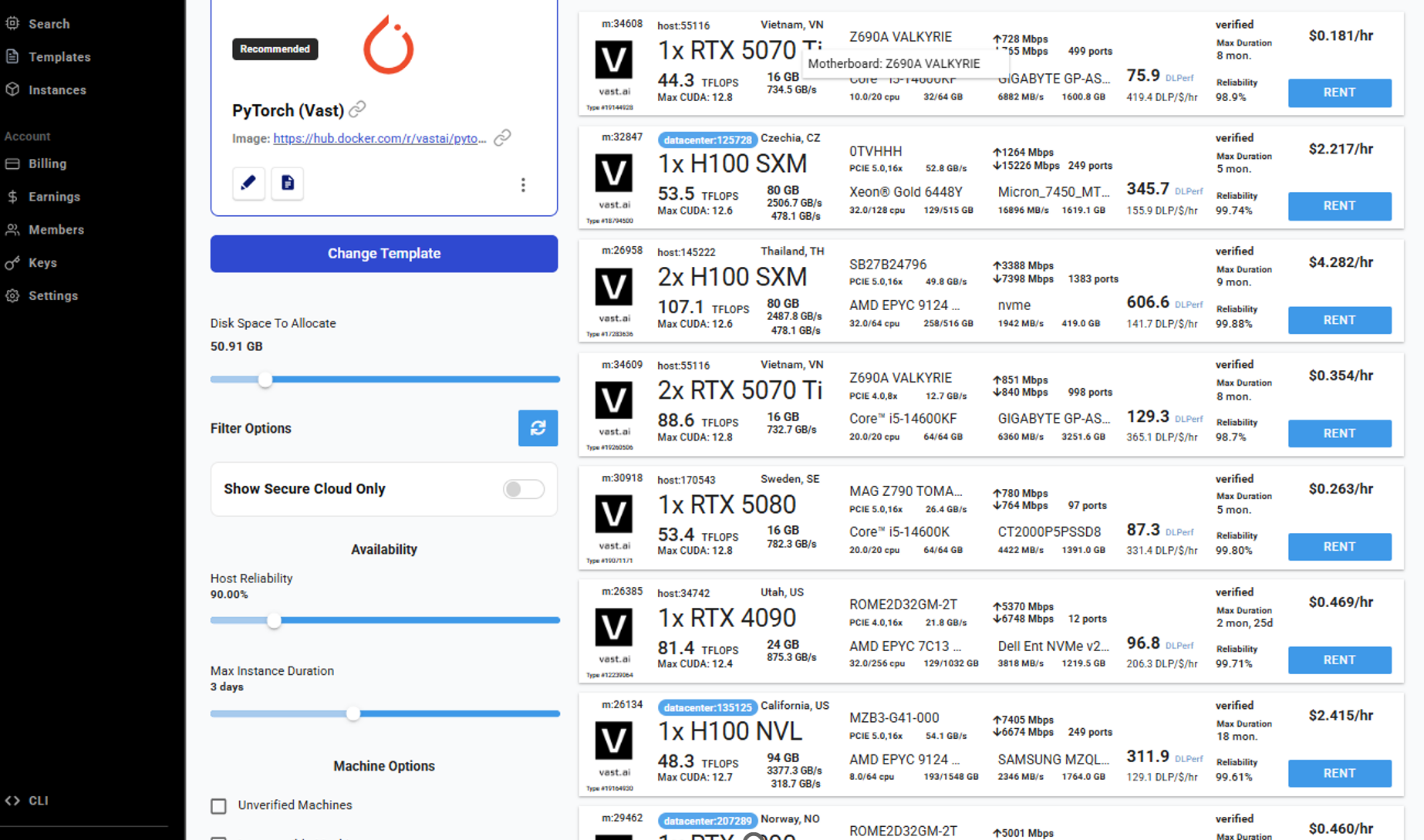
此处注意,很多GPU实例其实运行不起来。该平台本质是创建GPU直连的docker容器,注意检查日志是否有报错,有报错的实例直接删除就可以了。
只能过滤出来自己希望使用的显卡,然后一个一个试(不用担心试太多容器会花钱,他这没跑起来的容器不花钱),知道观察到这个按钮是Connecting, Open说明这个实例可以用起来。
如下,RTX5090,显存32GB:
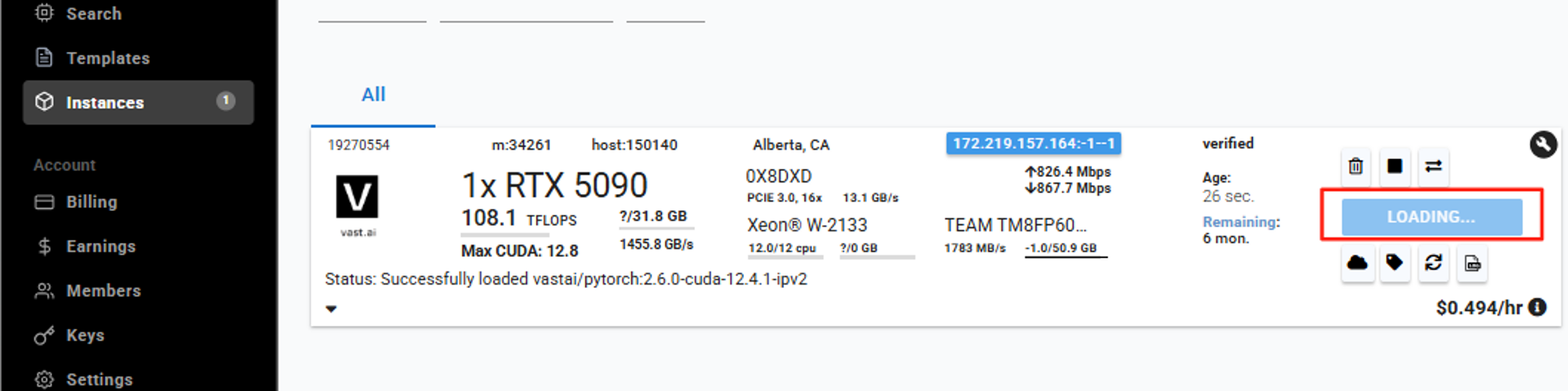
如图所示,确实可以运行:
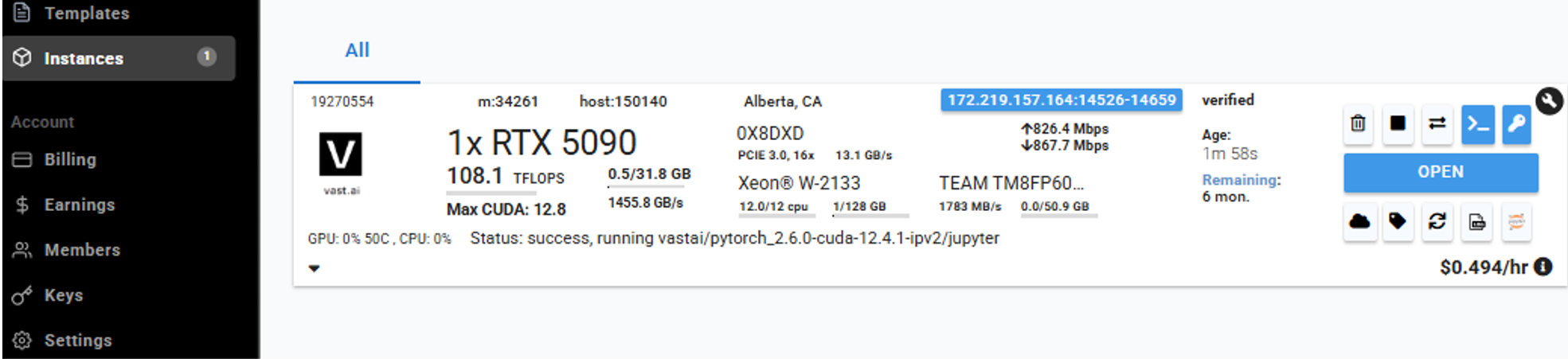
通过JupyterLab连接实例
点自己实例的Open按钮(此处我没有试成功直接的SSH连接)
Open后跳转的页面的这两个Application可以完成的文件上传下载、修改代码、执行shell。
我习惯点Jupyter Terminal 然后点开 Jupyter Lab.
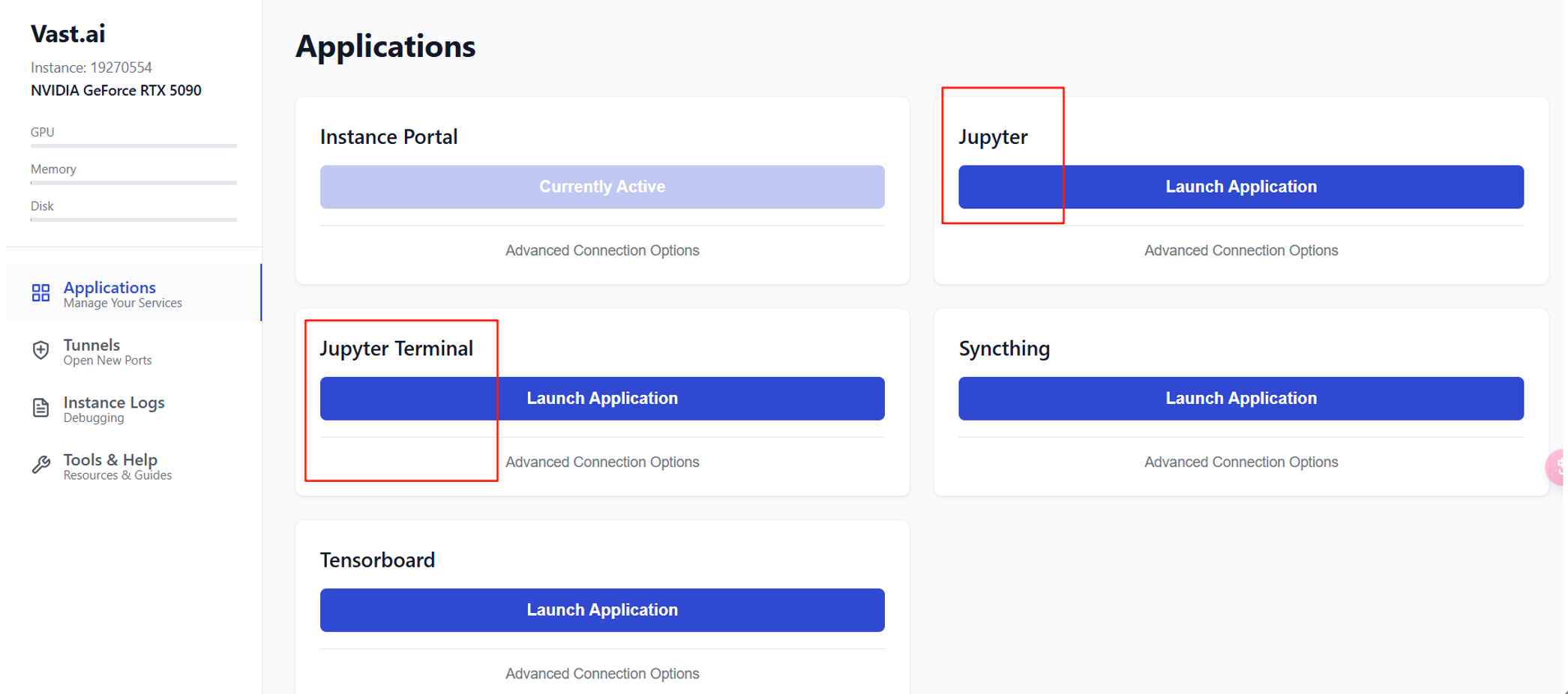
此处可以轻易的通过拖拽来文件IO(速度很快),也可以通过terminal运行shell。上传下载文件的时间你大概出去吃一顿饭。比如这24GB的文件费了大概半个小时。
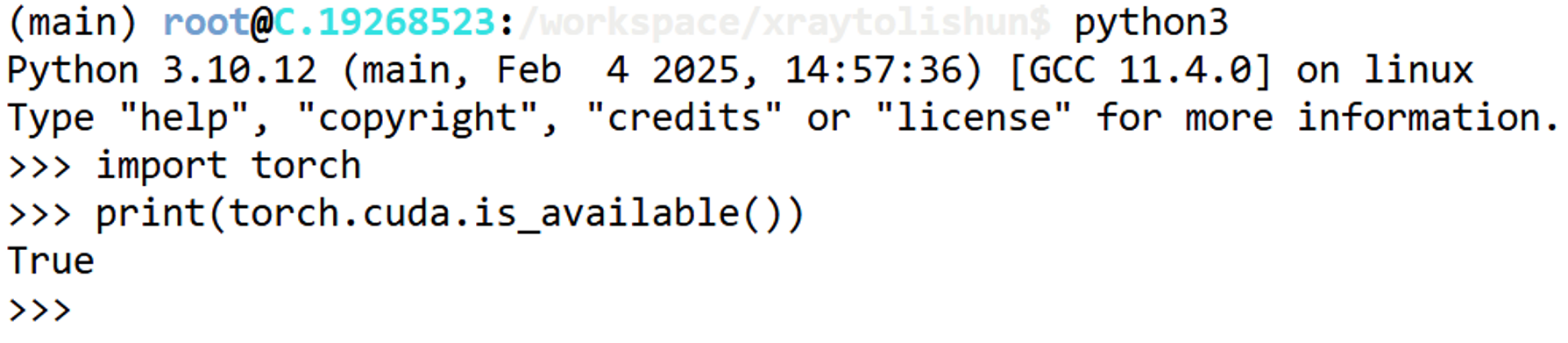
有能调用CUDA的torch
可以看到RTX4090的24G的显存,满功耗450W(我这里用另一个实例跑yolo任务)
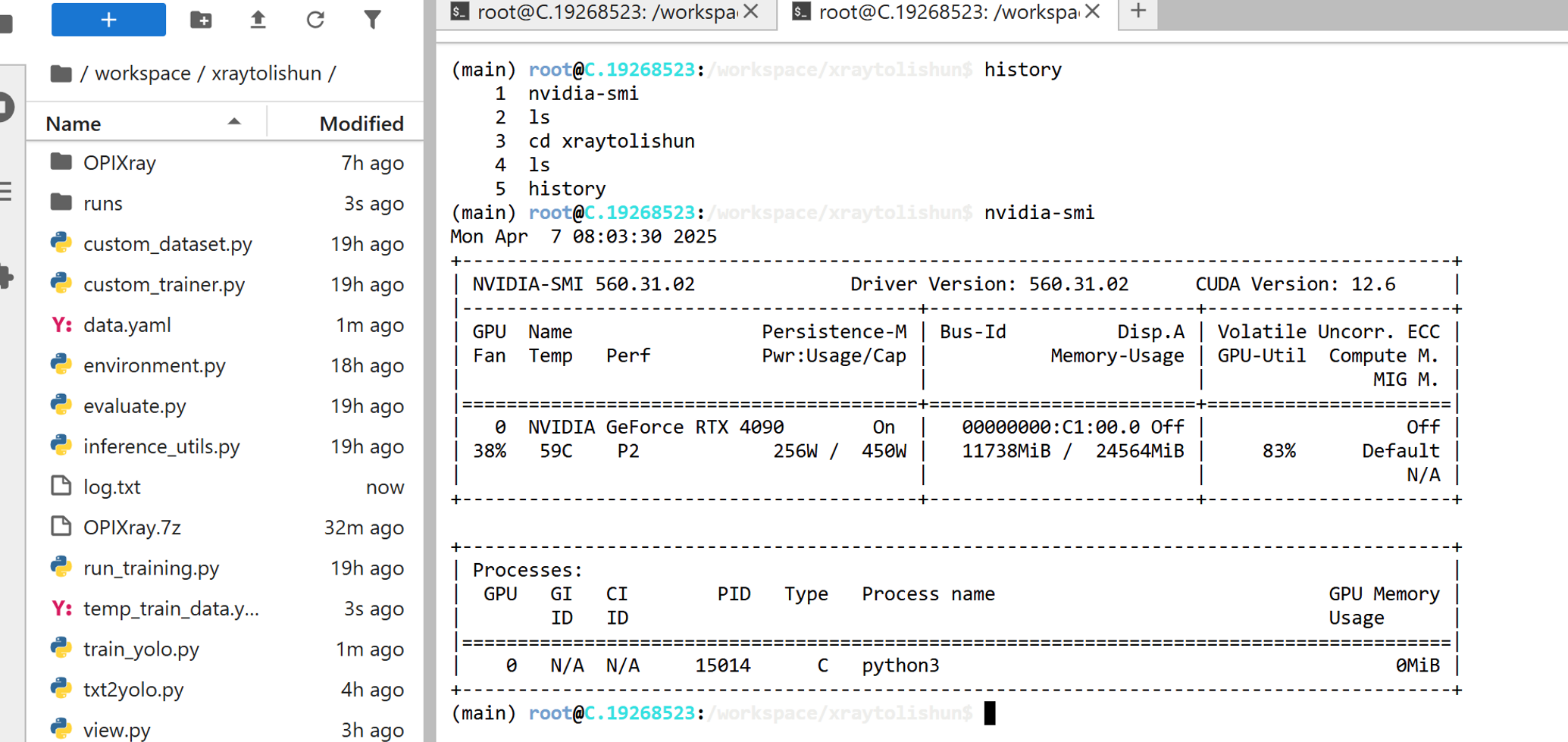
开始训练
pip缺什么库自己补全:如pip install ultralytics
摆好yolo的训练姿势
图片、label依次放入如下目录:
/test/images
/test/labels
/train/images
/train/labels
data.yaml
# 图片路径
train: /workspace/train
val: /workspace/test
# 类别信息
nc: 5
names: ["xxx1", "xxx2", "xxx3", "xxx4", "xxx5"]
train_yolo.py
略
使用screen让训练后台运行
如果你知道SSH会话一断,相关的子进程都不会运行。
此处我们需要后台训练,因为时间耗费比较长,我们也可能关掉基于WEB的SSH会话。
apt install screen
创建yolo会话
screen -S yolo
现在就进入yolo的screen了。
将标准输出、错误输出,定向到》./log 文件,方便我们未来查看当前yolo运行到什么程度了:
python train.py > ./log.txt 2>&1
完成后 ctrl+A + D (顺序按下)退出当前screen。
如果想切回之前的yolo的screen会话:
screen -ls 查看screen的后台会话
(main) root@C.19270554:/workspace$ screen -ls
There is a screen on:
1911.yolo (04/07/25 07:49:53) (Detached)
1 Socket in /run/screen/S-root.
screen -r 1911.yolo 切回输入命令的会话。
查看日志:(不需要进入screen会话),直接查看文件即可:tail命令可以查看这个日志
tail -f ./log.txt
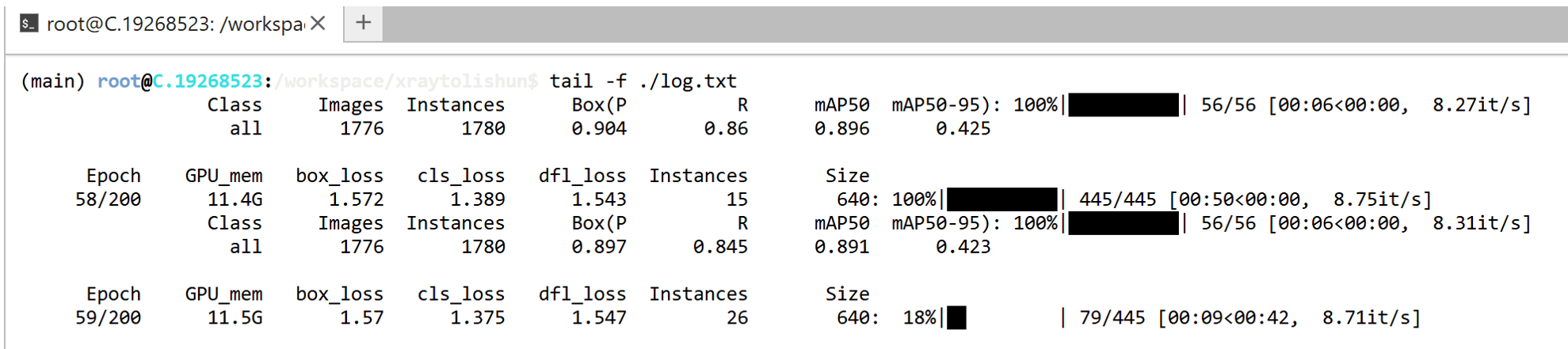
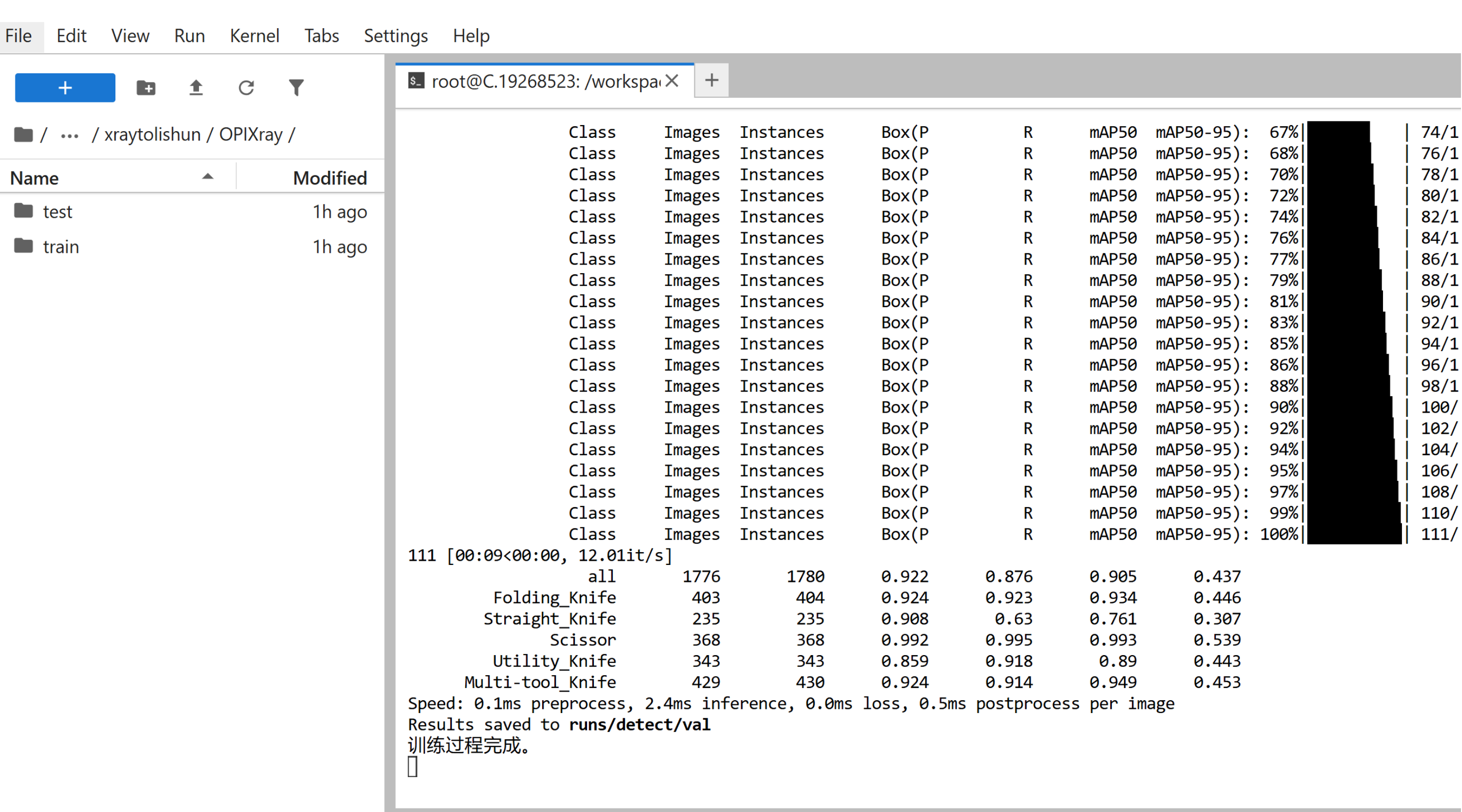
跑了大概两小时,跑100轮 16 batch,跑完了:
Welcome to point out the mistakes and faults!